一文带你读懂 WaveNet:谷歌助手的声音合成器
翻译| 酱番梨、王立鱼、莫青悠、Disillusion
校对、整理| 菠萝妹
一文带你读懂WaveNet:谷歌助手的声音合成器
有没有想过有可能使机器合成的人类声音几乎和人类本身的声音一样自然? WaveNet使其成为可能。
语音合成. 波音拼接合成. 参数合成. 深度学习.
机器合成拟人化语音(文语转换)的想法已经存在很长时间了。在深度学习出现之前,存在两种主流的建立语音合成系统的方式,即波音拼接合成和参数合成。
在波音拼接合成的文语转换中,它的思路就是通过收集一个人的一长列句子的发声录音,将这些录音切割成语音单元,尝试着将那些和最近提供的文本相匹配的语音单元进行拼接缝合,从而生成这文本对应的发声语音。通过波音拼接合成产生的语音,对于那些文本已经存在于用于初始收集的录音之中的部分,文语转换后的语音听上去比较自然,但是那些初次遇见的文本,就会听上去有些异样。除此之外,修饰声音要求我们对整个新录音集进行操作。反之在参数合成的文语转换中,它的思路是通过参数物理模型(本质上来说就是一个函数)来模拟人类的声道并使用记录的声音来调整参数。通过参数合成文语转换生成的声音听上去没有通过音波结合文语转换生成的声音那么自然,但是这种方式更容易通过调整某些模型中的参数来修饰声音。
近日来,随着WavNet的面世,对我们来说以端对端(来自声音记录本身)的方式来生成未处理的声音样本成为可能,可以简单的修饰声音,更重要的是和现存的语音处理方式相比,得到的声音明显的更加自然。所有的一切都要感谢深度学习的出现。
为什么WaveNet会让人如此的激动?
为了能够描绘出WaveNet和现存的语音合成方法的区别,采用了主观5分平均意见分法(MOS)测试进行统计。在平均意见分测试中,提供给对象(人)从各个声音合成系统中合成的声音样本,并被要求以5分制来评估样本的自然度(1:很差2:较差3:一般4:好5:优秀)。
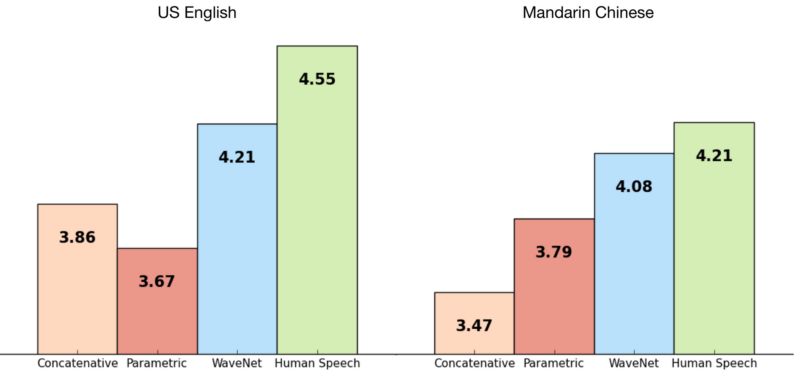
用于主观5分平均意见分法的声音样本分别从基于长短期记忆-循环神经网络(LSTM-RNN)的参数合成,基于隐马尔可夫模型(HMM)的语音单元集的波音拼接合成,和基于WaveNet的语音合成得到的。
从柱状图中可以清晰看到,WaveNet在5分制中得到了大概4.0分左右,很明显是优于其他的系统基线的,并且非常接近真实的人类声音。查阅了DeepMind’s blog 可以认识到在合成的语音的自然度方面这些方法的区别所在。除了能够输出合成的语音样本,WaveNet能够轻松的适应各种各样的语音特性,如:文本,发言者特性等,来生成满足我们需求的声音。这使它更加的令人感到激动。
WaveNet. 生成式模型.
生成式模型。这是指什么呢?给出的一般的未标记的数据点,一个生成式模型会尝试去学习什么样的概率分布可以生成这些数据点,目的是为了通过利用学习分布来产生新的数据点(与输入数据点相似)。生成式模型可以通过不同的方式对概率分布建模,隐式(具有可处理或近似密度)或者显式。当我们说一个生成式模型是显式建模模型的话,意味着我们明确的定义概率分布并尝试去适配每一个输入的未标记数据点。与它形成对比,一个隐式生成式模型学习一个概率分布,可以直接取样新数据点而不需要明确的定义。GANs(生成对抗网络),目前深度学习领域的圣杯,就属于隐式生成式模型。然而,WaveNet和它的表亲Pixel CNNs/RNNs(像素卷积神经网络模型/递归神经网络模型) 都属于显示生成式模型。
WaveNet如何明确的建立概率分布模型?WaveNet试图对一个数据流X的联合概率分布建立模型,对数据流X中的每一个元素Xt的条件概率求乘积。因此对于一段未处理音波X = {X1, X2, X3 … XT},构建的联合概率函数如下:

每一个样本Xt 因此而受限于所有的先前时间步长的样品。在一个时间步长上的观察结果取决于先前时间步长的观察结果(这就是我们试图使用每一个条件分布项去构建的模型),这看上去难道不像是一个时间序列预测模型吗?事实上,WaveNet是一个自动回归模型。
我们要如何去对这些条件分布项进行建模呢?RNs(递归神经网络模型)或者LSTMs(长短记忆网络模型)作为强有力的非线性时序模型是最显而易见的选择。事实上,像素递归神经网络使用同样的思路来生成与输入的图像相似的合成图像。我们可以使用这种思路来生成合成语音吗?语音是从至少16KHZ的频率取样,这意味着,每秒的音频至少有16000个样本。RNNs(递归神经网络)或者LSTMs(长短记忆网络)还未曾对如此长(大约10000时间步长序列)的时间依赖性进行建模,他们目前能建模的最长时间依赖性是100时间步长序列,因此这两种模型并不能很好的适用于语音合成。我们能否适用CNN(卷积神经网络)来处理呢?等一下,CNNs(卷积神经网络模型)?如何做到呢?相似的思路已经被使用于像素卷积神经网络模型中了。
卷积神经网络模型. 因果卷积. 膨胀卷积.
版权保护: 本文由 沃派博客-沃派网 编辑,转载请保留链接: http://www.bdice.cn/html/27129.html


