潮科技行业入门指南 | 深度学习理论与实战:提高篇(3)——基于HMM的语音识别
编者按:本文节选自《深度学习理论与实战:提高篇 》一书,原文链接http://fancyerii.github.io/2019/03/14/dl-book/。作者李理,环信人工智能研发中心vp,有十多年自然语言处理和人工智能研发经验,主持研发过多款智能硬件的问答和对话系统,负责环信中文语义分析开放平台和环信智能机器人的设计与研发。
以下为正文。

HMM模型自从1980年代被用于语音识别以来,一直都是实际语音识别系统的主流方法。即使到了今天,End-to-End的语音识别系统不断出现,在工业界很多主流的系统仍然还是在使用基于HMM模型的方法,当然很多情况引入了深度神经网络用来替代传统的GMM模型。因此我们首先来了解一些经典的基于HMM模型的语音识别系统。
语音产生过程
语音的激励来自于肺呼出的气体,声门的不断开启和闭合会产生周期的信号,这个信号的频率就叫基音频率(fundamental frequency F0),如下图所示,这个信号的基频是150Hz。
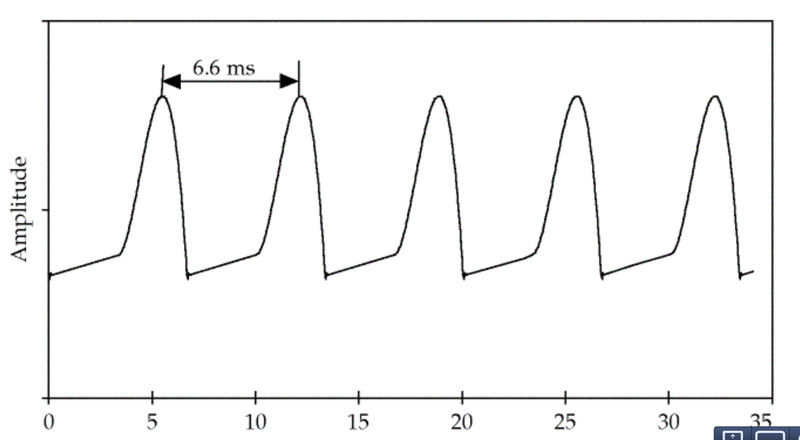
图:基音频率 图片来自课程cs224
除了150HZ的基音频率,它也会产生300Hz、450Hz…的信号,这些叫做泛音(harmonics),最终得到的信号的频谱如下图所示。
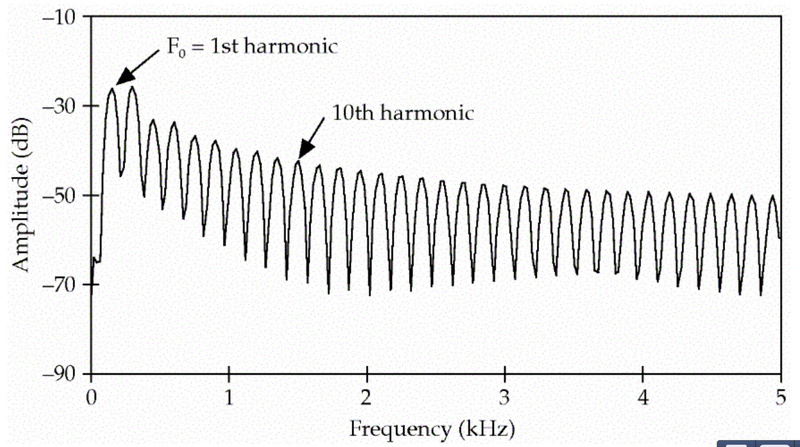
图:Harmonics 图片来自课程cs224
每个人的基音频率都是不同的,同时一个人也要发出各种不同的声音,这是怎么实现的呢?原理人在发不同音的时候声道、口腔、舌头、牙齿和鼻腔等发音器官会处于不同的开合状态,比如发a的时候口长得比较开,发s的时候我们让舌头和上牙之间有一个很小的缝隙,从而产生摩擦的声音。从信号处理的角度来说,这些发音器官的不同状态就产生了不同的滤波器。
我们每个人的基频虽然不同,但是在发相同的音的时候产生的滤波器都是类似的,因此我们每个人说”你好”的最终信号虽然不同,但是我们的口腔等发音器官的状态是类似的。因此我们也可以把发声看做如下图所示的过程。
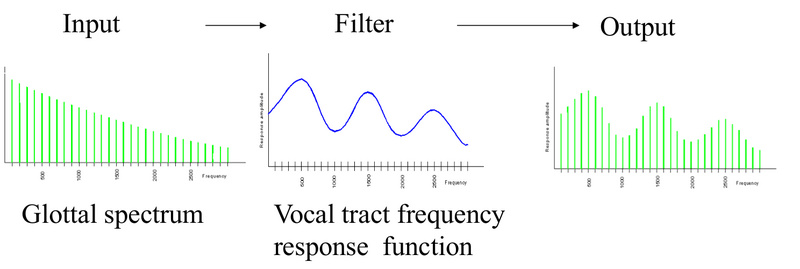
图:source-filter模型 图片来自课程cs224
我们的呼吸带动声门的开闭产生的信号叫源(source),我们的声道等发声器官是滤波器(filter),它们作用的结果就是最终的语音信号。
听觉感知过程
说话产生的声波在空气中的震动,然后会传到耳朵里。人的耳蜗在接收到声音信号时,不同的频率会引起耳蜗不同部位的震动。高频声波是使耳蜗底部基底膜振动;低频声波使耳蜗顶部基底膜振动;中频声波使基底膜中部发生振动。我们大致可以认为不同部位的纤毛会接收不同频率的声波,因此耳蜗就像一个频谱仪,虽然它没有学习过傅里叶变换,但是它知道怎么进行傅里叶分析。因此为了模拟人类的听觉,我们通常需要把时域的信号变换成频域的信号。关于傅里叶分析,这个教程非常直观,建议读者阅读。
信号处理
为了能让计算机处理,我们首先会使用麦克风把声压转换成电信号,如下图所示。工作的时候麦克风的膜片(membrane)会随着声波振动,从而把声波转换成不断变化强度的电信号。
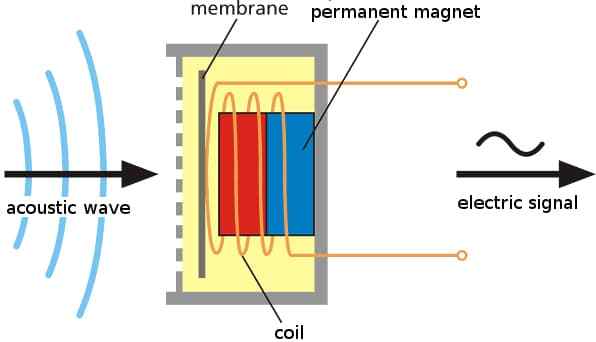
图:麦克风把声音变成电信号
为了便于计算机处理,我们需要把模拟的电信号转换成数字信号。这就需要ADC(Analog-to-Digital Conversion)把模拟信号转换成数字信号,它包括采样和量化两个步骤。因为人类的语音来说,我们说话产生的声音的频率范围是小于8KHz的,根据奈奎斯特和香农采样定理,我们的采样频率只要达到16KHz(采样频率指的是每秒钟从模拟信号抽样的点的个数),那么就可以完全通过采样点恢复出原始信号。人类的听觉极限一般是20Hz-20KHz,因此CD一般使用44.1KHz的采样频率。采样过程如下图所示,因此采样把一个时间轴连续的信号变成离散的信号。
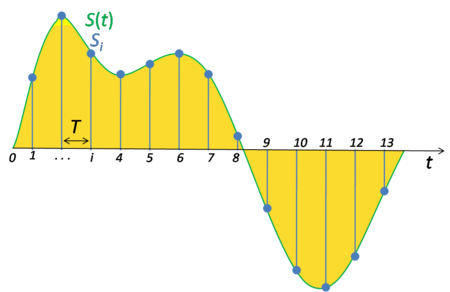
图:采样
采样之后,我们的信号点由无穷个变成了有限个,但是信号的值还是一个连续的实数,所以我们需要使用量化技术把它离散化。
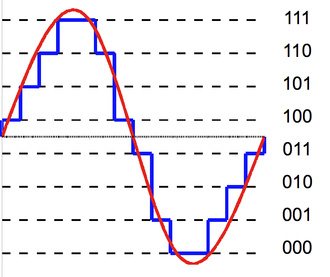
图:量化
版权保护: 本文由 沃派博客-沃派网 编辑,转载请保留链接: http://www.bdice.cn/html/46737.html


